집합 연산의 이해와 활용
<집합 연산이란>
: 2개 이상의 쿼리 결과에 대해투플을 원소로 하는 집합 연산 수행 -> 하나의 결과로 출력
<사용 경우>
1. 동일 테이블에서 서로 다른 질의를 수행하여 결과를 합치고자 할 때
- OR: predicate 또는 합집합 가능
- AND: 원자성 때문에 반드시 교집합만 사용 가능
- FULL OUTER JOIN: 양쪽 테이블 데이터 모두 보존(조인조건 만족 x -> NULL)
- 다차원 분석 기반 OLAP 구현: GROUP BY와 집합 연산(UNION ALL) 활용
2. 서로 다른 테이블에서 집합 가능한 컬럼 구성 결과 얻고 이를 하나로 합칠 때
보고서 작성할 때처럼 의미상 다르지만 형식이 같은 컬럼들 합칠 때
UNION, INTERSECT, EXCEPT 연산과 'ALL' 옵션
'UNION': 합집합
'INTERSECT': 교집합
'EXCEPT': 차집합
'ALL' 옵션: 결과에 중복 투플 포함
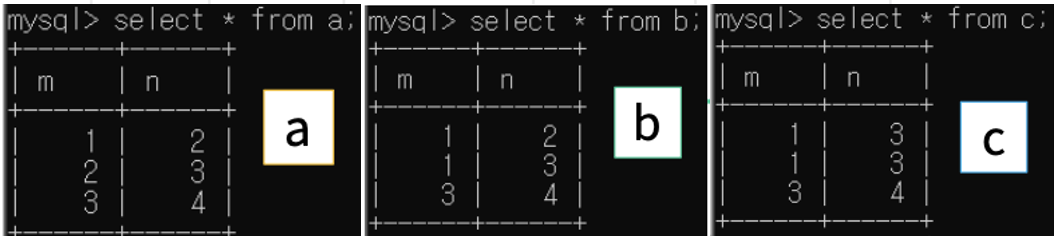
1. 'UNION': 합집합
(select * from a) union (select * from b); //중복 없음(디폴트)
(select * from a) union all (select * from b); //중복 포함
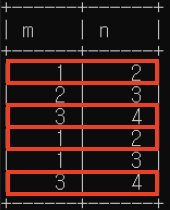
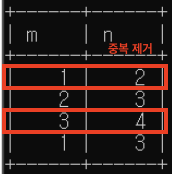
2. 'INTERSECT': 교집합
(select * from c) intersect (select * from c); //중복 없음(디폴트)
(select * from c) intersect all (select * from c); //중복 포함

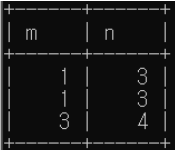
3. 'EXCEPT': 차집합
(select * from c) except (select * from a); //중복 없음(디폴트)
(select * from c) except all (select * from a); //중복 포함

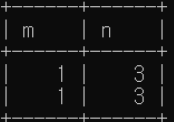
적용 가능한 경우
1. 동일 기준에 대한 AND 조건 처리
=> 교집합해서 가능
2017년 가을 학기와 2018년 봄 학기에 모두 개설된 강의(course_id)를 조회하라.
(select course_id from section where semester = 'Fall' and year = 2017)
intersect
(select course_id from section where semester = 'Spring' and year = 2018);


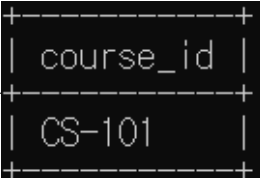
2. FULL OUTER JOIN 구현
FULL OUTER JOIN = LEFT OUTER JOIN ∪ RIGHT OUTER JOIN
=> FULL 안 쓰고도 LEFT와 RIGHT를 합집합해 구할 수 있음
(select ac.actor_no "actor_no(ac)", //left outer join
ac.guarantee "guarantee_cur",
ap.actor_no "actor_no(ap)",
ap.movie,
ap.guarantee "guarantee_then"
from actor ac left outer join appearance ap
on ac.actor_no = ap.actor_no)
union //합집합
(select ac.actor_no "actor_no(ac)", //right outer join
ac.guarantee "guarantee_cur",
ap.actor_no "actor_no(ap)",
ap.movie,
ap.guarantee "guarantee_then"
from actor ac right outer join appearance ap
on ac.actor_no = ap.actor_no);
다차원 분석 기반 OLAP
범주형 컬럼(차원) 단위의 분석
| 주요 연산 | 의미 | 연산에 주어지는 컬럼 (문법 x 표기법 o) |
집계 기준 컬럼 조합 |
| ROLL UP | 계층별 집계 (왼쪽에 기재된 컬럼을 높은 계층으로 간주) |
ROLL UP(a, b, c) * 왼쪽에 있을수록 더 높은 계층에 있는 컬럼(여기서는 c->b->a 순으로 높음) |
(a, b, c), (a, b), (a), () * (): 전체 테이블 |
| ROLL UP(a, b) | (a, b), (a), () | ||
| CUBE | 기재된 컬럼들로 가능한 모든 컬럼 조합 기준 집계 | CUBE(a, b, c) | (a, b, c), (a, b), (b, c), (a, c), (a), (b), (c), () |
| CUBE(a, b) | (a, b), (a), (b), () | ||
| GROUPING SETS | 기재된 각 컬럼 기준 집계 | GROUPING SETS(a, b, c) | (a), (b), (c) |
| GROUPING SETS(a, b) | (a), (b) | ||
| PIVOT | 주어진 두 범주형 속성 컬럼 값의 조합 쌍에 대한 cross-tab 생성 (한 컬럼의 속성 값들은 행, 다른 컬럼의 속성 값들은 열에 배치 -> timetable과 유사한 형태) |
||
(시험에 나옴) "각 조합에 대해서 연산에 어떤 컬럼이 주어졌을 때 연산 별로 집계 기준이 되는 컬럼 조합을 써라"
<예제>: "sales" 스키마
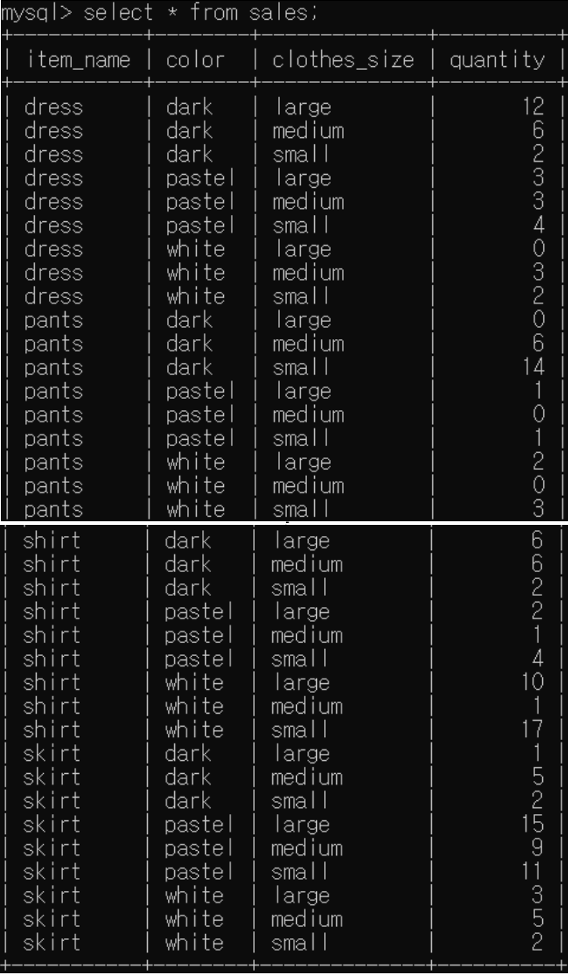
컬럼 계층: item_name > color > clothes_size
ROLL UP과 CUBE가 각각 "(item_name, color)"를 해석하는 방법이 다르다.
- ROLL UP: (item_name, color), (item_name), ()
- CUBE: (item_name, color), (item_name), (color), ()
<ROLL UP>
select item_name, color, sum(quantity)
from sales
group by item_name, color with rollup; // item_name, color 컬럼에 대해 rollup 연산 수행
ROLL UP(item_name, color) -> (item_name, color), (item_name), ()
* (): 전체 테이블 대상 집계
(point) (item_name, color), (item_name), () 이 무슨 의미인지 알아야 하고, sum(quantity)를 채울 수 있어야 함
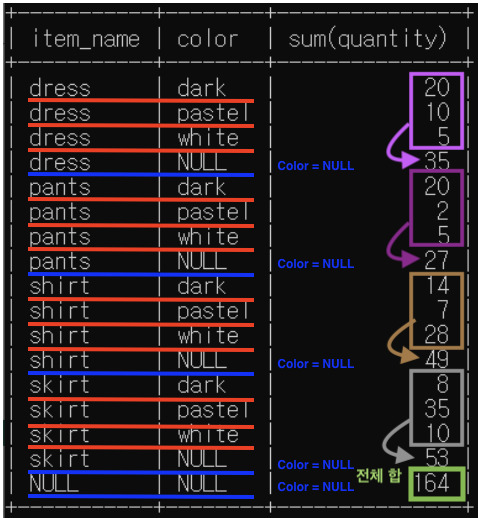
- 빨간색: (item_name, color)
- 파란색: (item_name) => color은 NULL => 앞 빨간색 포괄
<CUBE>
"~별 집계" 라는 의미를 가지고 있으므로 -> group by로 묶을 수 있고 각 group by 결과들을 union all로 묶어주면 됨

<GROUPING SETS>
1. GROUPING SETS (item_name, color) -> (item_name), (color)
: item_name이 다른 것끼리 묶고
color가 다른 것끼리 묶음

2. GROUPING SETS ((item_name, color)) -> (item_name, color)
: item_name과 color가 모두 다른 것끼리 묶음

<PIVOT>
주어진 두 범주형 속성 컬럼 값의 조합 쌍에 대한 cross-tab 생성
한 컬럼의 속성값들은 행, 다른 컬럼의 속성 값들은 열에 배치 -> timetable과 유사 (보통 for 보고서 작성)

'백엔드 > SQL' 카테고리의 다른 글
| 관계 데이터베이스 설계 - 함수 종속성과 정규화 (0) | 2025.05.28 |
|---|---|
| 데이터베이스 설계와 개체-관계 모델 (0) | 2025.05.27 |
| SQL을 활용한 데이터 집계와 분석(1) (0) | 2025.05.24 |
| JOIN (0) | 2025.04.17 |
| DML: SQL 연산자와 내장함수(2) (0) | 2025.04.15 |



