OLAP(Online Analytical Processing)
OLAP이란
대용량 데이터를 다양한 차원의 관점에서 빠르게 분석 및 집계(요약)하기 위한 온라인 분석 처리 기법
- 시간, 지역, 제품, 고객 등 다양한 속성별 관점에서 데이터 탐색 가능
- 경영진, 분석가들이 의사결정을 위한 통찰을 얻기 쉬움
- 의사결정을 위한 보고서 작성에 도움을 줄 수 있는 세부 분석 기법들로 구성
주로 의사결정 지원 시스템 또는 데이터 웨어하우스에서 사용되는 분석 기법
-> OLAP 전용 엔진 및 이를 지원하는 전용 쿼리 언어 활용
일반적인 관계형 데이터베이스에서도 다양한 관점의 분석 및 요약을 위해 사용 가능
-> SQL에서 확장 지원하는 구문 활용
주로, 기업용 RDBMS에서만 지원되기 때문에 MySQL Community 등 무료 RDBMS에서 미지원되는 구문은 SQL로 직접 구현 가능하다.
<"차원"이란?>
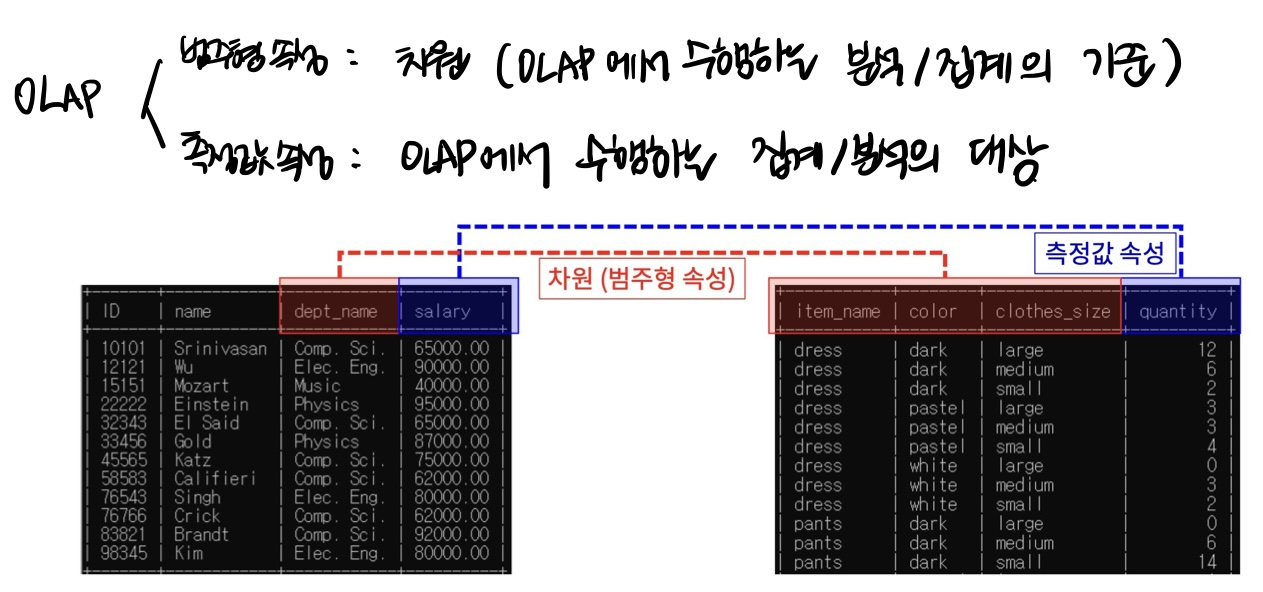
OLAP의 목표: 범주형 속성(차원)을 기준으로 측정값 속성을 분석하는 것
<종류>
| 분류 | 윈도우 함수 기반 OLAP | 다차원 분석 기반 OLAP |
| 분석 기준 | 행 단위 (하나의 행이 다른 행들과의 관계 속에서 갖는 의미) |
컬럼 단위 (범주형 값을 갖는 컬럼들의 조합 기준으로 집계) |
| 목적 | 시간 또는 특정 순서에 따른 누적 집계 및 순위 분석 (행끼리 비교) |
범주형 속성 값 기준의 집계 |
| 응용 | 시계열 분석, 사용자 행동 분석 | 통계 요약, 보고서 작성에 필요한 집계 결과 생성 |
| 지원 RDBMS | - 무료 및 유료 버전의 RDBMS 모두에서 지원 - MySQL Community 8.0 이상, MySQL Enterprise 8.0 이상, Oracle 등 |
- MySQL Community 8.0은 일부(ROLLUP)만 지원 → 나머지는 직접 구현해야 함 - MySQL Enterprise 8.0 이상은 모두 지원 - Oracle은 XE(무료 버전)와 유료 버전 모두 지원 |
| 사용법 | OVER() 함수와 집계 또는 순위 함수를 함께 사용 - OVER(): 집계 대상 윈도우 정의 - 집계 함수: SUM, AVG, MIN, MAX 등 - 순위 함수: RANK, DENSE_RANK 등 |
- GROUP BY 절과 전용 분석 연산 구문을 함께 사용 - 미지원 구문은 직접 구현 (UNION ALL, CASE 활용) |
| 대표적인 연산 | - OVER을 통해 정의된 윈도우 단위의 누적 집계 (SUM, AVG, MIN, MAX, 각종 통계 함수 적용 가능) - OVER을 통해 정의된 윈도우 단위의 순위 계산 (RANK, DENSE_RANK, ROW_NUMBER) |
- ROLL UP - CUBE - GROUPING SETS - PIVOT |
윈도우 함수 기반 OLAP
: 매 행에 대해 정의
over()이 있으면 "윈도우 함수 기반이구나!" 라고 생각하면 됨
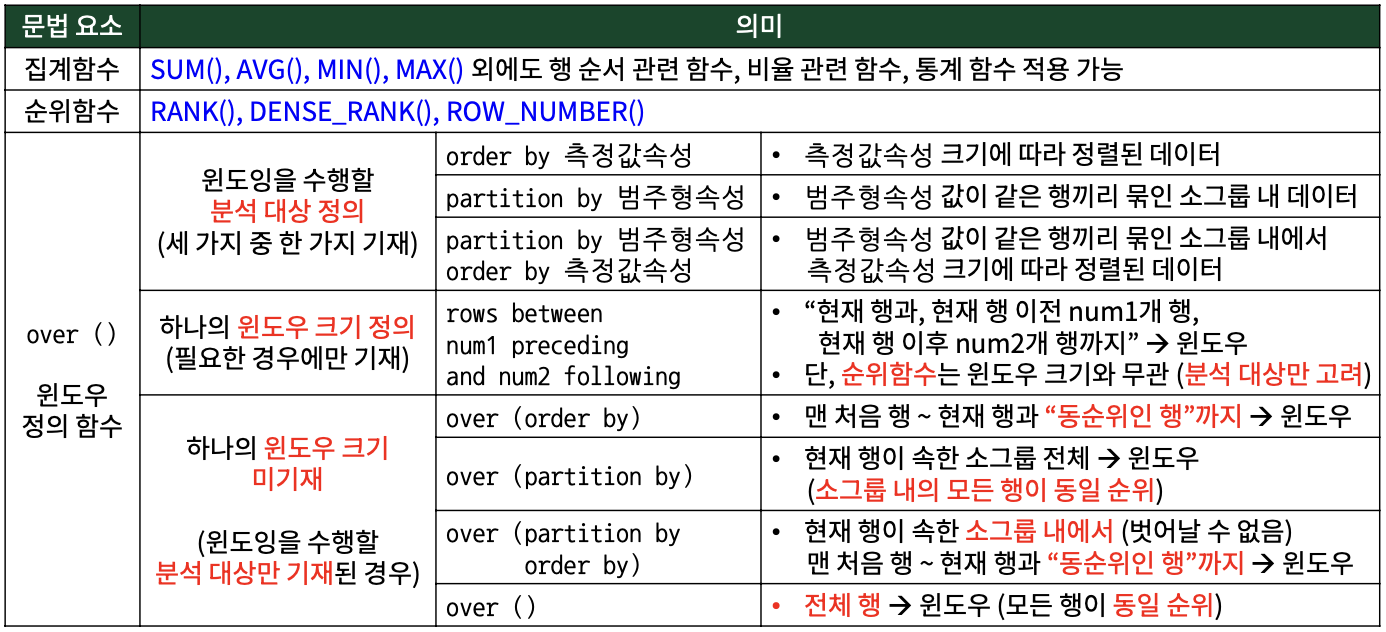
select 조회가 필요한 컬럼들,
[집계함수 | 순위함수] over ([order by 측정값 속성] 또는 //윈도우 분석 대상 정의(필수/세 개 중 하나 택)
[partition by 범주형 속성] 또는
[partition by 범주형 속성 order by 측정값 속성]
[rows between num1 preceding // 윈도우 크기 정의(선택)
and num2 following] 선택적 추가) as 윈도잉_결과 //'윈도잉_결과': 결과 컬럼
from 집계대상테이블;
동작 과정
"over 안쪽에 윈도우 분석 대상 정의에 따라 윈도우(행 묶음) 정의
-> 그 윈도우에 대해 집계/순위함수 적용
-> 결과를 결과 컬럼(윈도잉_결과)에 넣어줌"
1행: 윈도우 대상 정의로 빨간색에 들어있는 2개의 행 선택 -> 집계작업(ex. sum) -> 1행 윈도잉_결과에 salary의 합 들어감
2행: 파란색에 들어있는 3개의 행 선택 -> 집계작업(ex. sum) -> 2행 윈도잉_결과에 salary의 합 들어감
8행: 노란색에 들어있는 3개의 행 선택 -> 집계작업(ex. sum) -> 8행 윈도잉_결과에 salary의 합 들어감
10행: 초록색에 들어있는 3개의 행 선택 -> 집계작업(ex. sum) -> 10행 윈도잉_결과에 salary의 합 들어감

<예제1>: 분석대상 order by만 / 윈도우 크기 x
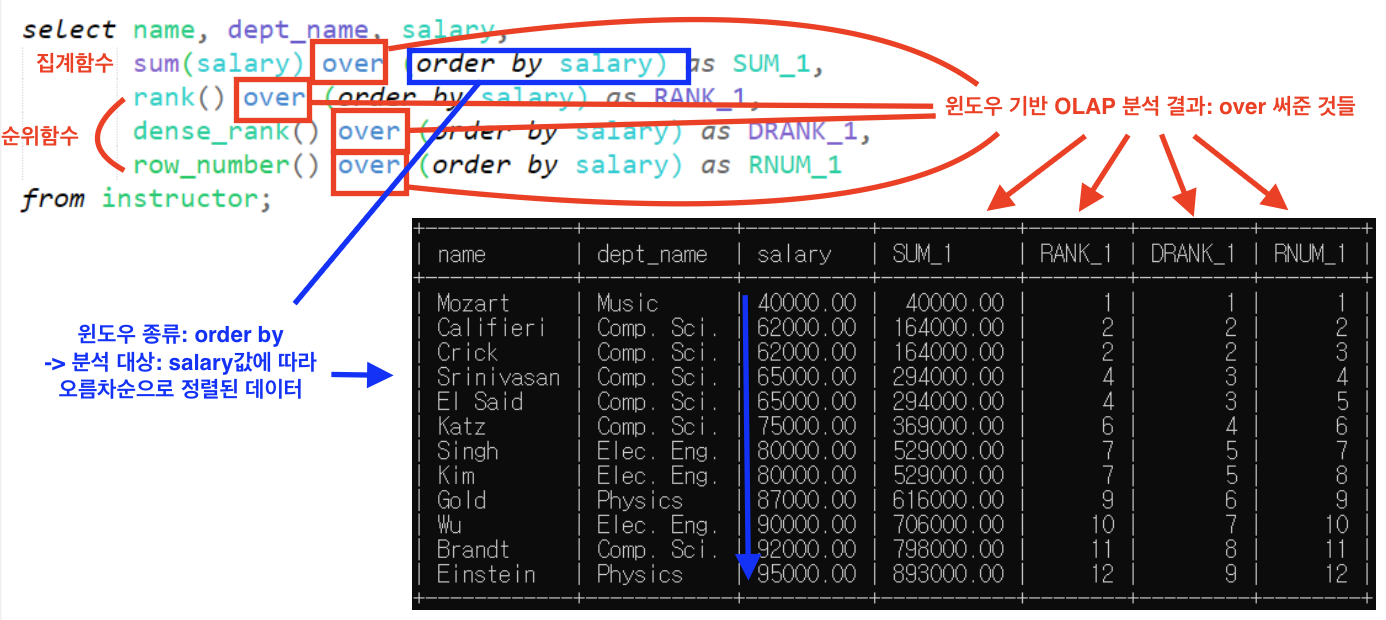
over 뒤에 윈도우 분석 대상 -> 집계함수 -> 결과 컬럼(SUM_1, RANK_1, DRANK_1, RNUM_1)에 집계 결과 적어줌
1. 집계함수
sum(salary) order (order by salary) as SUM_1
(1) 1번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우 없음 -> 선택된 행만 윈도우
- sum 함수 실행
* 윈도우가 한 행뿐이므로 그냥 40000 적어줌
(2) 2번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 3번째 행
-> 윈도우: 1,2,3번째 행
- sum 함수 실행
* 윈도우 행들 salary 합 -> 40000+62000+62000=164000 적어줌
(3) 3번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 2번째 행
-> 윈도우: 1,2,3번째 행
- sum 함수 실행
* 윈도우 행들 salary 합 -> 40000+62000+62000=164000 적어줌
(4) 4번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 5번째 행
-> 윈도우: 1,2,3,4,5번째 행
- sum 함수 실행
* 윈도우 행들 salary 합 -> 40000+62000+62000+65000+65000=294000 적어줌
(5) 5번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 4번째 행
-> 윈도우: 1,2,3,4,5번째 행
- sum 함수 실행
* 윈도우 행들 salary 합 -> 40000+62000+62000+65000+65000=294000 적어줌
6번째~끝 행도 동일한 방법으로..

2. 순위함수
<rank(): 절대 순위>
rank() over (order by salary) as RANK_1
(1) 1번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우 없음 -> 선택된 행만 윈도우
- rank 함수 실행: 1순위이므로 1
(2) 2번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 3번째 행
-> 윈도우: 1,2,3번째 행
- rank 함수 실행: 2순위이므로 2
(3) 3번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 2번째 행
-> 윈도우: 1,2,3번째 행
- rank 함수 실행: 2번째 행과 순위 같으므로 2
(4) 4번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 5번째 행
-> 윈도우: 1,2,3,4,5번째 행
- rank 함수 실행: 순위 4이므로 4
(5) 5번째 행
- order by: salary 컬럼이 오름차순으로 정렬된 상태
* 현재 행과 동순위인 행(salary값이 같은 행)이 윈도우: 4번째 행
-> 윈도우: 1,2,3,4,5번째 행
- rank 함수 실행: 4번째 행과 순위 같으므로 4
6번째~끝 행도 동일한 방법으로..

<dense_rank(): 상대 순위>
dense_rank() over (order by salary) as DRANK_1
rank와 같이 순위함수이지만, 중간에 없는 숫자가 없어야 함

<row_number(): 윈도우 결과 함수 내 행 번호>
row_number() over (order by salary) as RNUM_1
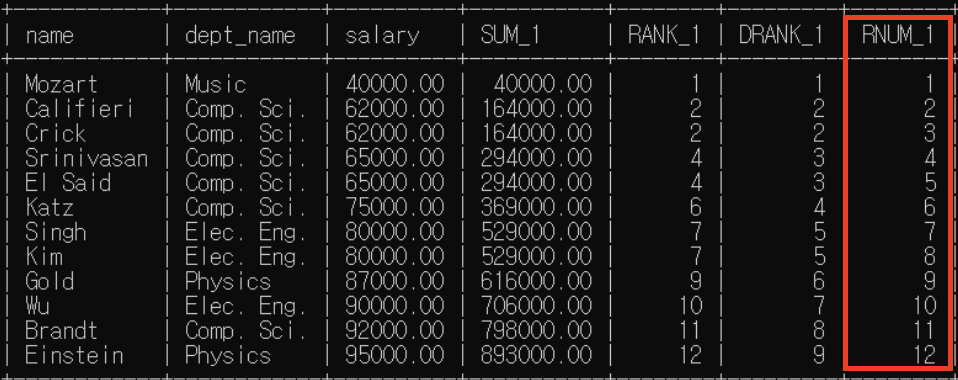
<예제2>: 분석 대상 order by만 / 윈도우 크기 명시
윈도우 크기 명시 -> 동순위 고려하지 않고 크기만 고려

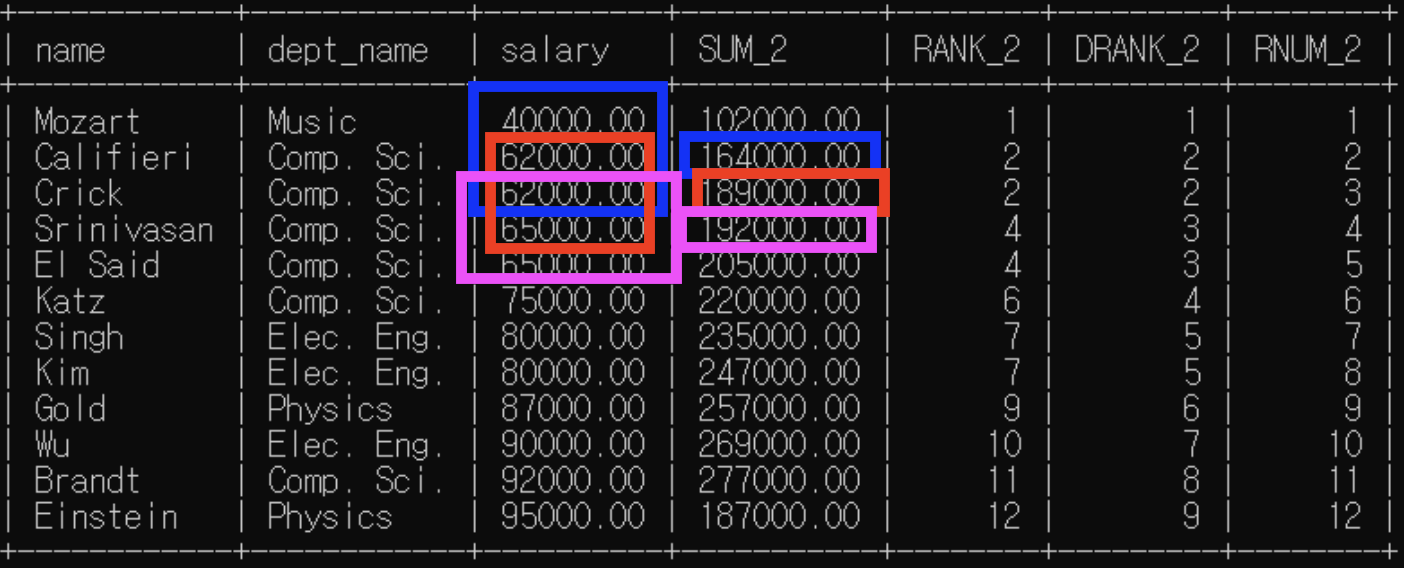
<예제3>: 분석 대상 partition by만 / 윈도우 크기 명시 x
partition by: 각 행에 대한 윈도우
* partition by만 있다면 윈도우 하나 내 모든 행은 동일한 순위
* partition by+order by 모두 있다면 같은 분석대상 내 행들 순위 매겨짐
ex. 1번째 행에 대한 윈도우는 그 행과 dept_name이 같은 소그룹 전체
<sum(): 합>
같은 윈도우 내에서는 모두 같음
<rank(): 절대 순위>
같은 윈도우 내에서는 모두 같음
-> 그냥 다 1이 됨
<dense_rank(): 상대 순위>
같은 윈도우 내에서는 모두 같음
-> 그냥 다 1이 됨
<row_number(): 윈도우 결과 함수 내 행 번호>
같은 윈도우 내에서만 순서 매김
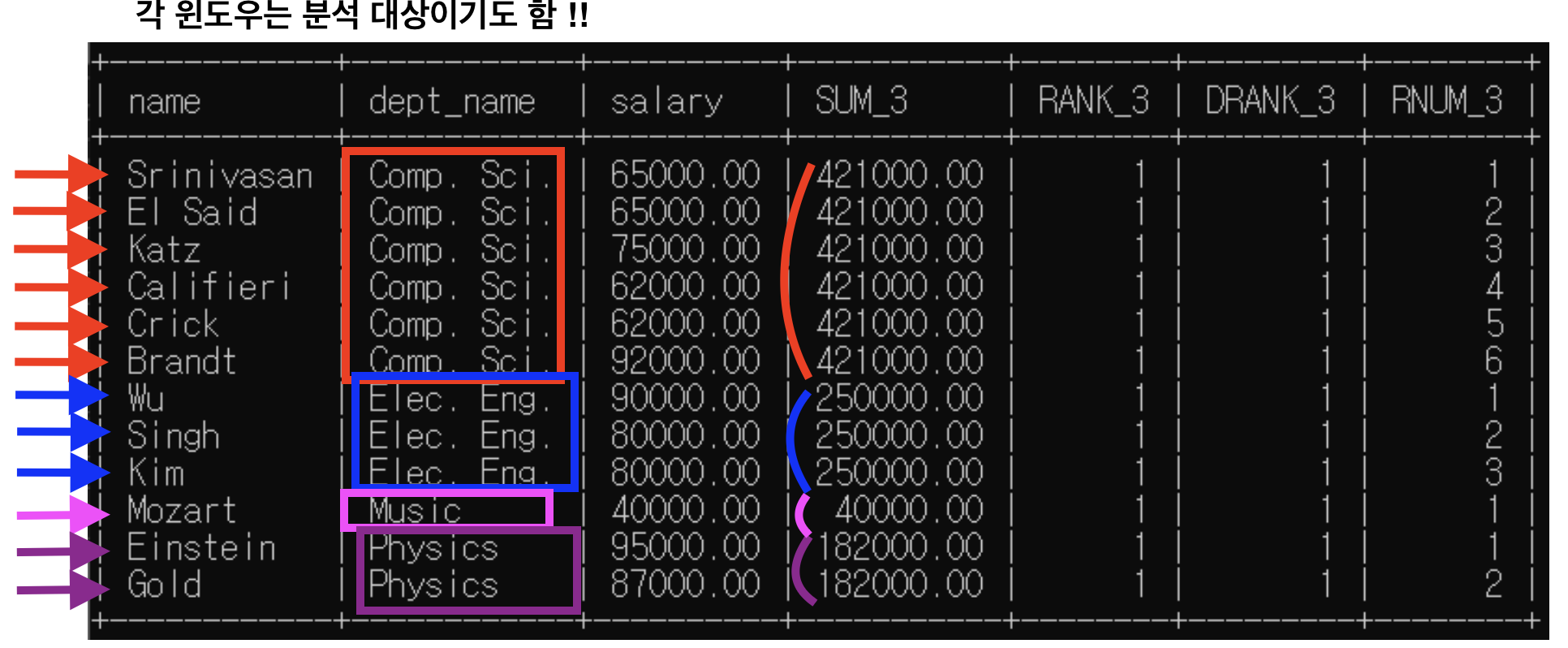
<예제4>: 분석 대상 partition by만 / 윈도우 크기 명시
윈도우 크기가 정해지더라도 partition by 범위 넘어갈 수 없음

<sum()>
sum(salary) over (partition by dept_name
rows between 1 preceding
and 1 following) as SUM_4
(1) 1번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- "rows between 1 preceding and 1 following" -> 윈도우 크기는 위 아래 행 하나씩
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum() 함수 실행: 65000+65000=130000

(2) 2번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- "rows between 1 preceding and 1 following" -> 윈도우 크기는 위 아래 행 하나씩
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum() 함수 실행: 65000+65000+75000=205000
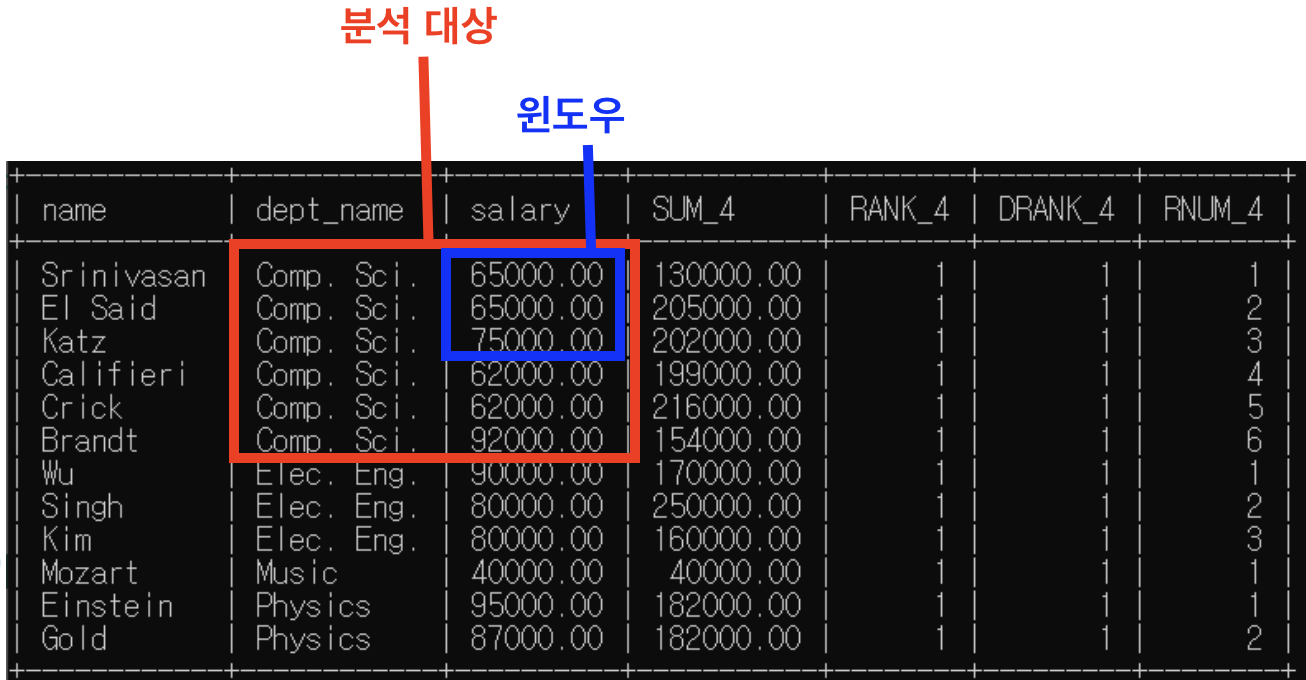
(3) 3번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- "rows between 1 preceding and 1 following" -> 윈도우 크기는 위 아래 행 하나씩
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum() 함수 실행: 65000+75000+62000=202000
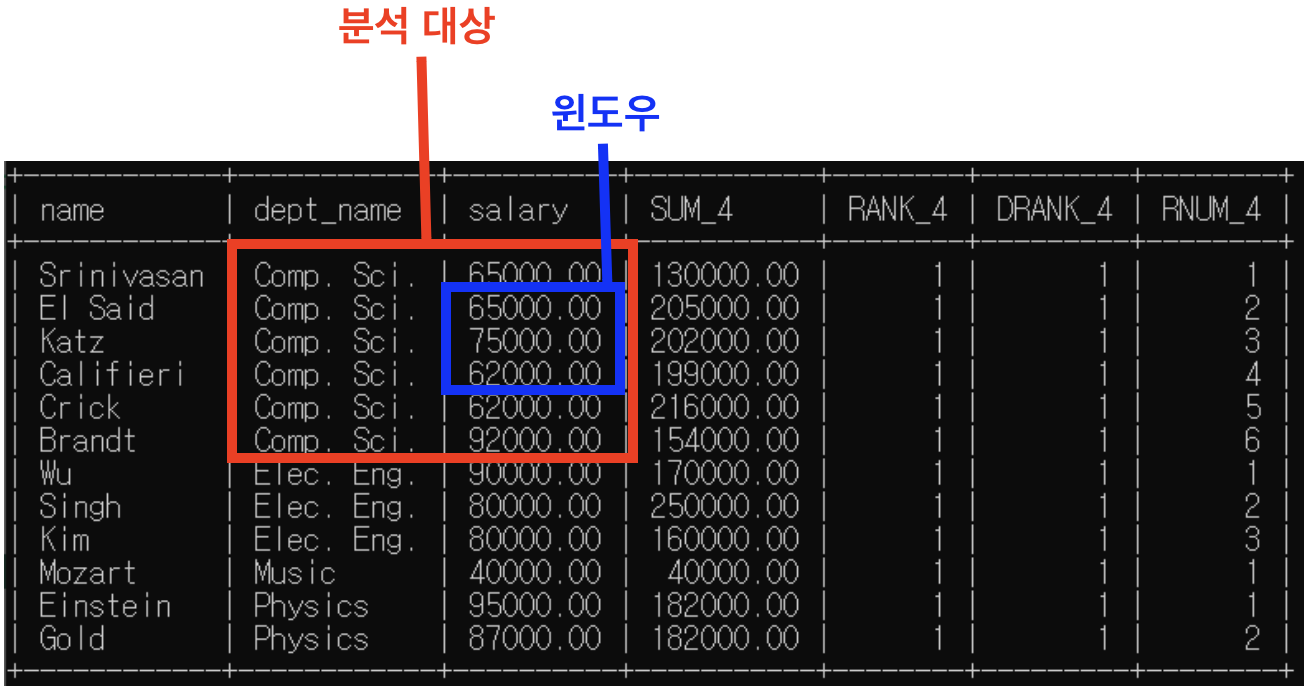
(4) 4번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- "rows between 1 preceding and 1 following" -> 윈도우 크기는 위 아래 행 하나씩
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum() 함수 실행: 75000_62000+62000=199000
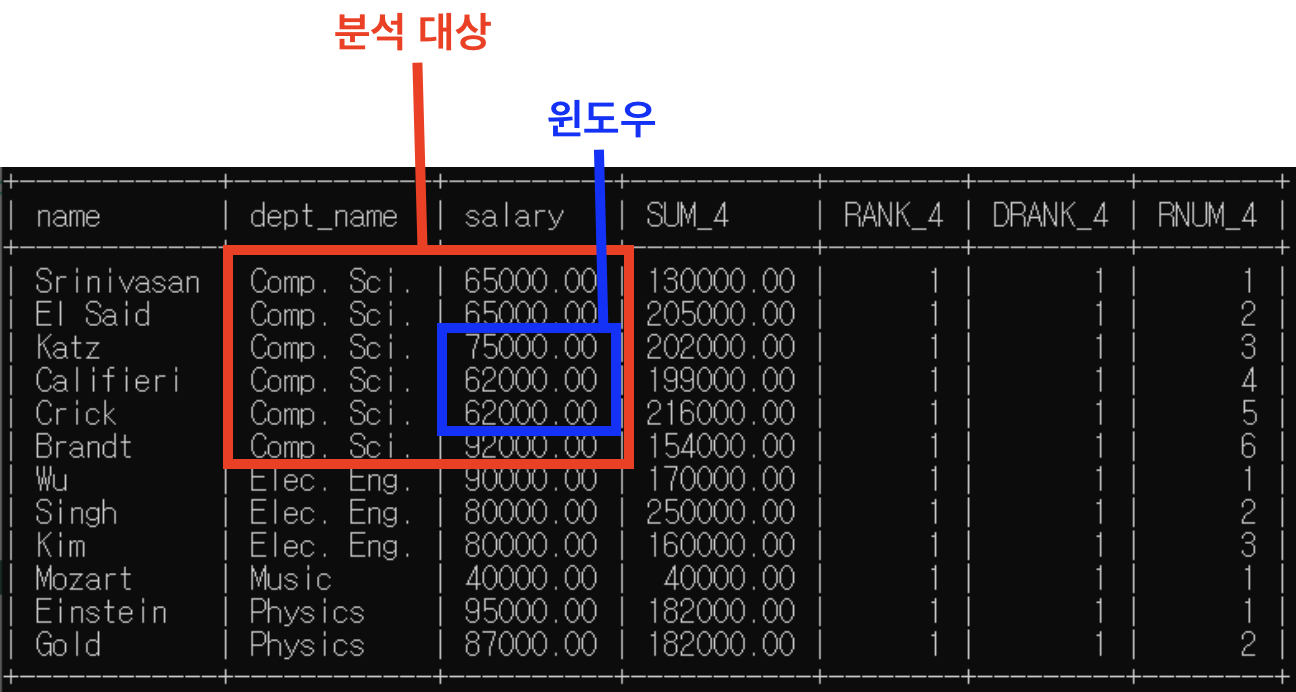
(5) 5번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- "rows between 1 preceding and 1 following" -> 윈도우 크기는 위 아래 행 하나씩
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum() 함수 실행: 62000+62000+92000=216000
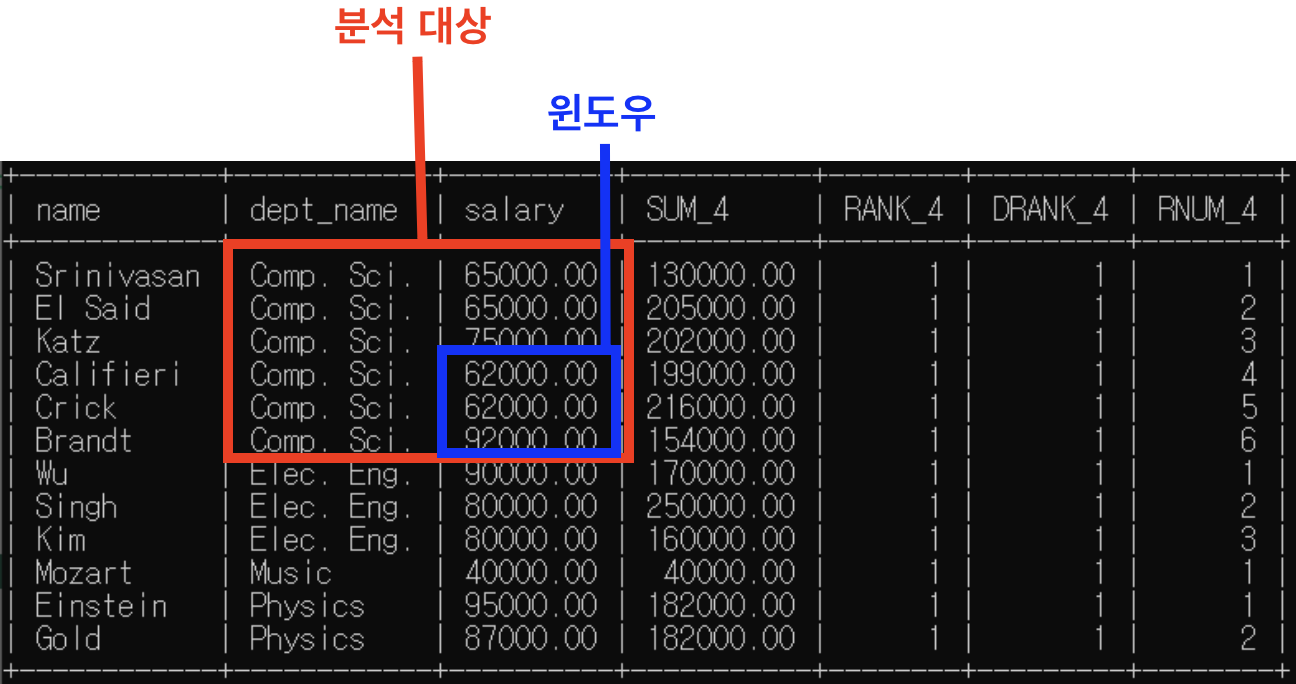
(6) 6번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- "rows between 1 preceding and 1 following" -> 윈도우 크기는 위 아래 행 하나씩 -> (중요)BUT 아래 행은 partition by 범위 넘어가기 때문에 제외
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum() 함수 실행: 65000+65000+75000=205000
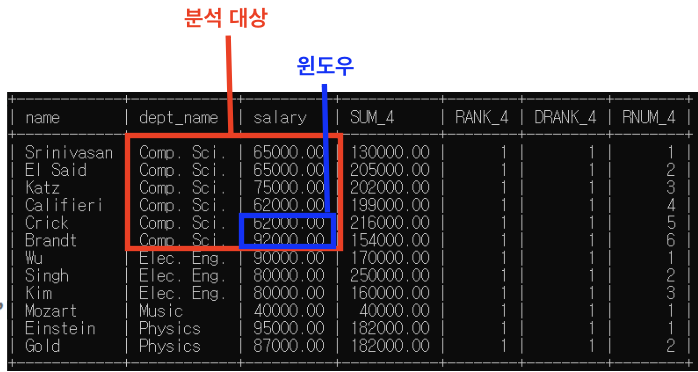
<rank()>
: 각자 분석 대상 내 행들은 동일 순위
rank() over (partition by dept_name
rows between 1 preceding
and 1 following) as RANK_4
<dense_rank()>
각자 분석 대상 내 행들은 동일 순위
dense_rank() over (partition by dept_name
rows between 1 preceding
and 1 following) as DRANK_4
<row_number()>
: 각자 분석 대상 안에서만 순위 매김 -> 다른 분석 대상으로 넘어가면 1부터 다시 시작
row_number() over (partition by dept_name
rows between 1 preceding
and 1 following) as RNUM_4
<예제5>: 분석 대상 partition by + order by / 윈도우 크기 x
한 분석대상 안의 salary 컬럼이(partition by) 오름차순 정렬(order by)

소그룹 내에서 order by -> 동순위끼리만 윈도우 지정하고 연산하기 위해 순위 매김
윈도우 크기 명시 x -> 윈도우 크기는 처음행~동순위 행
(1) 1번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- order by: 소그룹 내에서 동순위 차등 부여
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum(): 62000+62000=124000

(2) 2번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- order by: 소그룹 내에서 동순위 차등 부여
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum(): 62000+62000=124000
(3) 3번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- order by: 소그룹 내에서 동순위 차등 부여
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum(): 62000+62000+65000+65000=254000
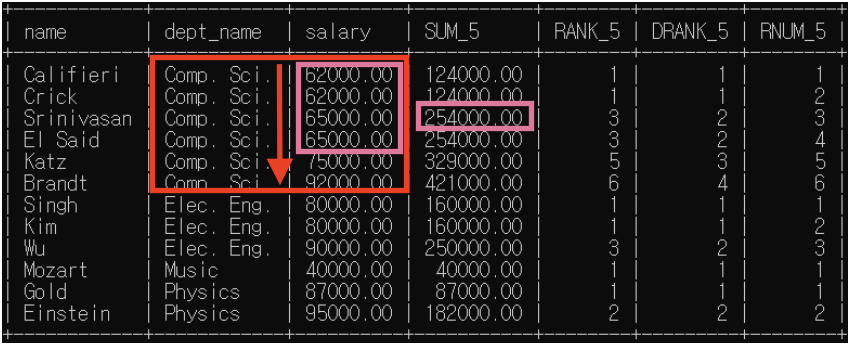
(4) 4번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- order by: 소그룹 내에서 동순위 차등 부여
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum(): 62000+62000+65000+65000=254000
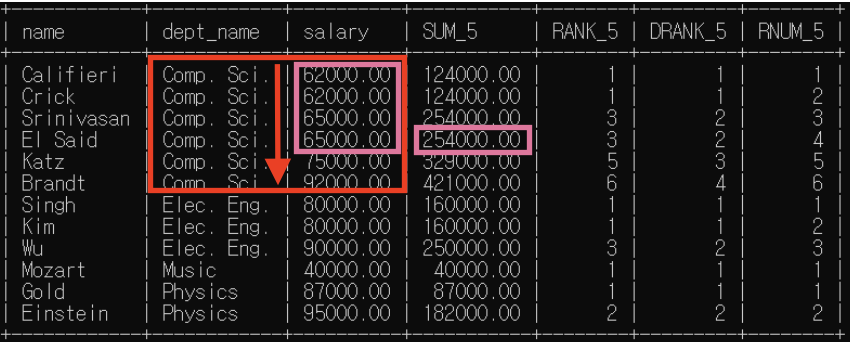
(5) 5번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- order by: 소그룹 내에서 동순위 차등 부여
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum(): 62000+62000+65000+65000+75000=329000
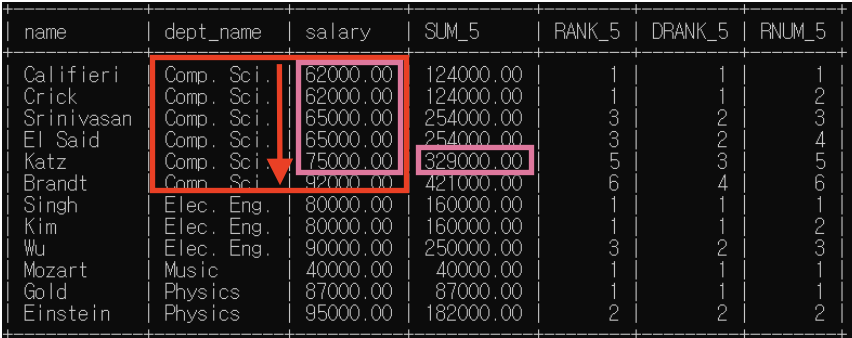
(6) 6번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- order by: 소그룹 내에서 동순위 차등 부여
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum(): 62000+62000+65000+65000+75000+92000=421000
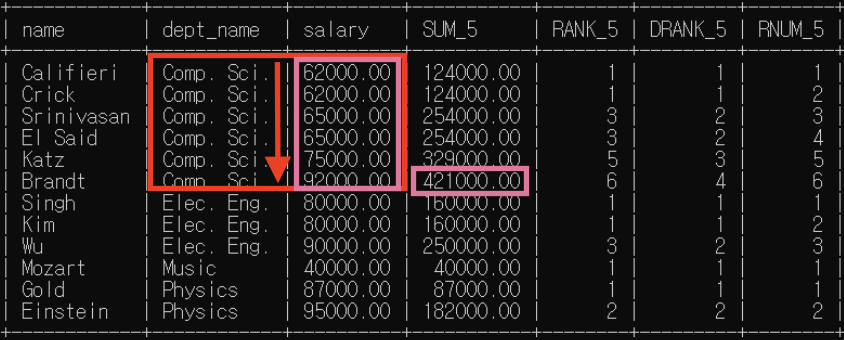
(7) 7번째 행
- partition by: dept_name별로 소그룹 분류해둠
* "dept_name=Comp.Sci."인 행들 소그룹 -> 이제 함수들 실행할 윈도우 이 범위 넘어갈 수 없음
- order by: 소그룹 내에서 동순위 차등 부여
=> sum()은 윈도우 기준으로, rank()/dense_rank()/row_number()은 분석대상 기준으로
- sum(): 80000+80000=160000

8~끝도 해보기
<rank()>
: 각자 분석 대상 내 행들 절대 순위 매김
<dense_rank()>
: 각자 분석 대상 내 행들 상대 순위 매김
<row_number()>
: 각자 분석 대상 안에서만 순위 매김 -> 다른 분석 대상으로 넘어가면 1부터 다시 시작
<예제6>: 분석 대상 partition by + order by / 윈도우 크기 명시
예제5에서 윈도우 크기가 위 아래 행 하나씩으로 명시되어 있는 예제다.
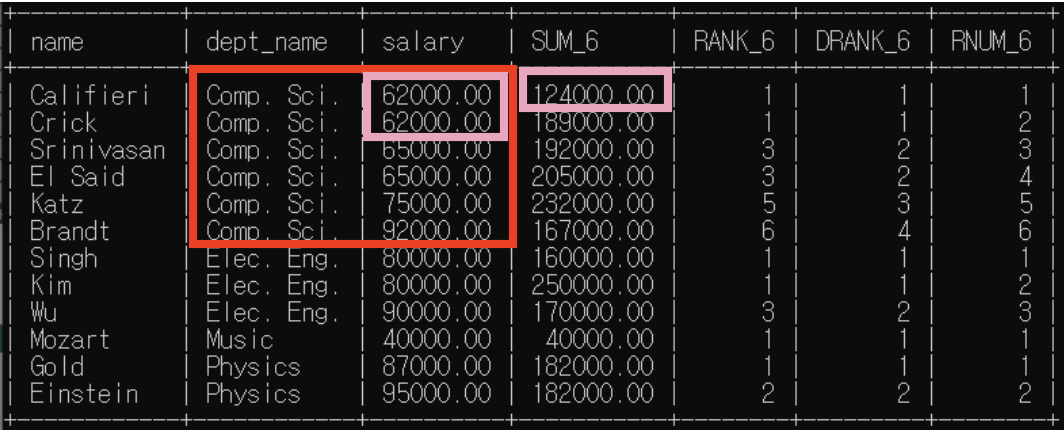





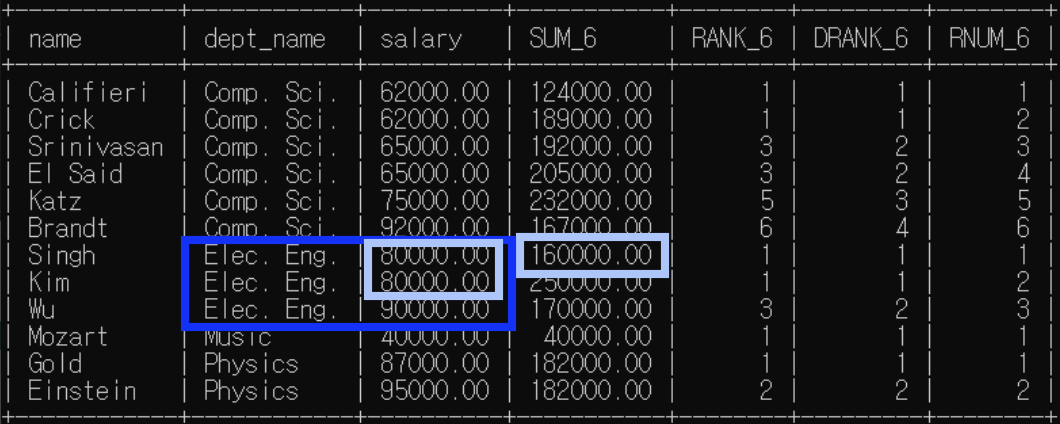
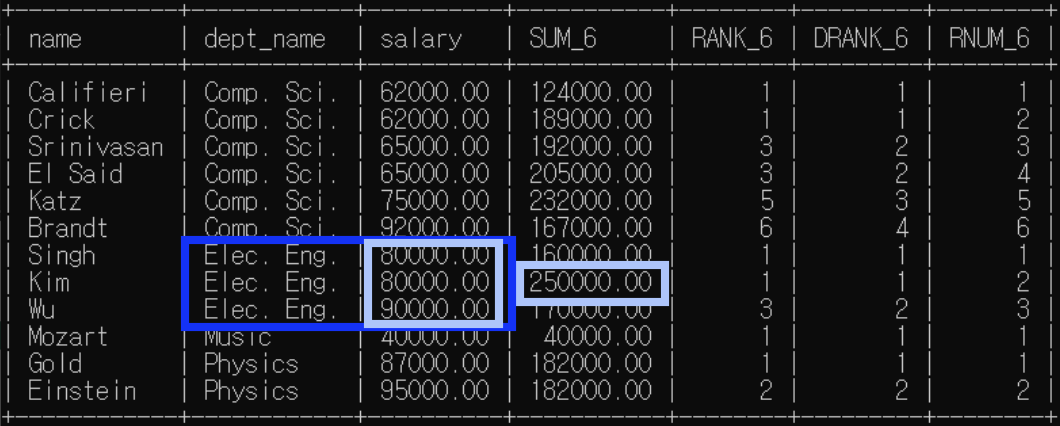
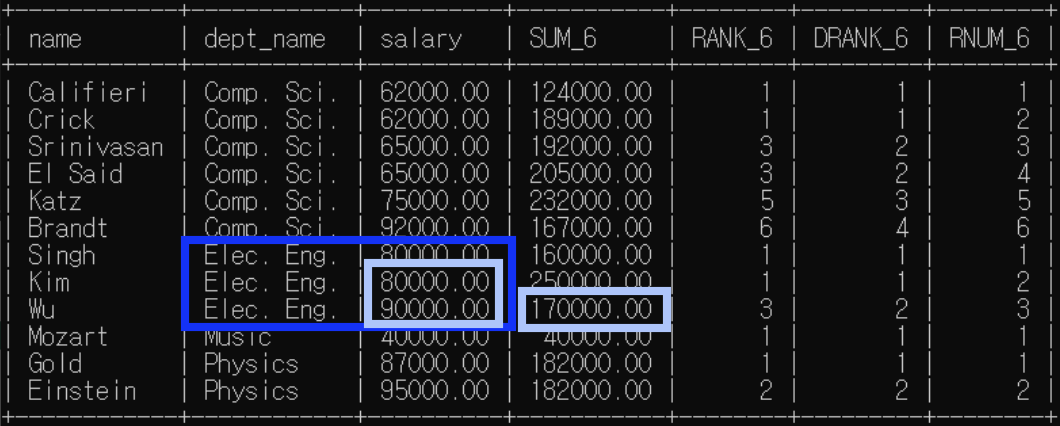
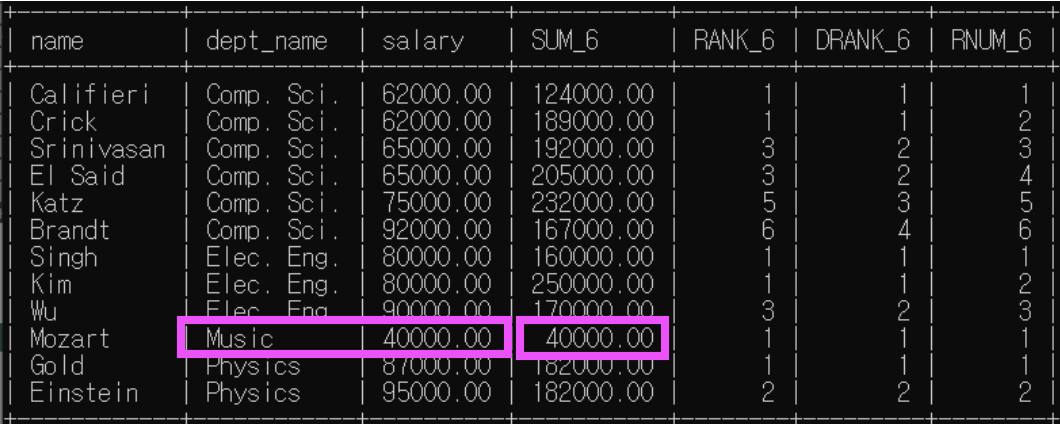
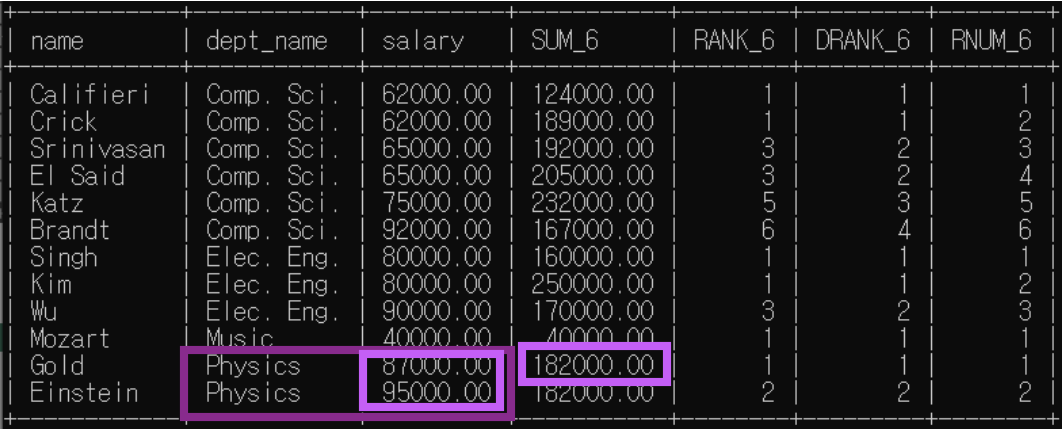
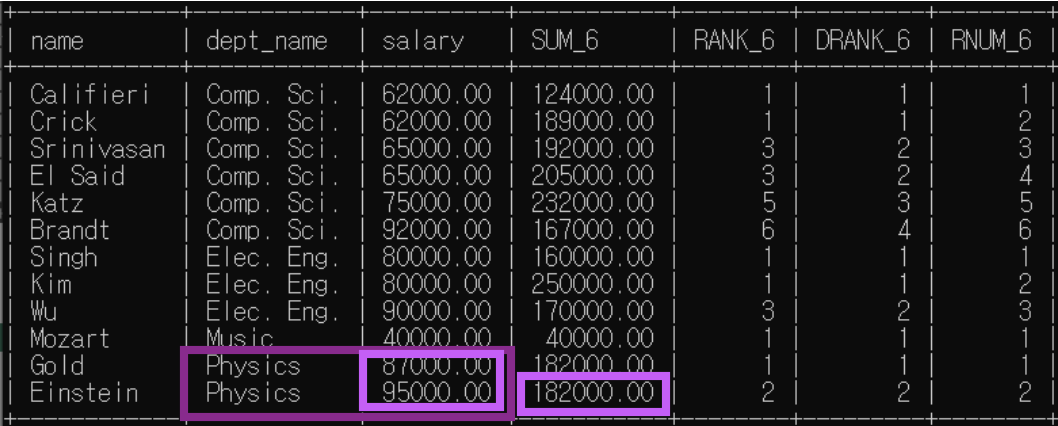
order by 존재하므로 rank(), dense_rank()은 한 분석 대상 내에서 순위가 매겨짐
<예제7>: 분석 대상 partition by + order by / 윈도우 크기 명시
윈도우 정의가 비어있을 때
-> 분석대상도, 윈도우 크기도 정해지지 않았기 때문에 전체 행을 하나의 윈도우이자 분석대상으로 본다.
전체 행이 동일 순위이기 때문에 rank(), dense_rank()은 모두 1이 되고, row_number()은 처음부터 끝까지 쭉 순위가 매겨진다.
또한 sum()은 전체 행의 salary값의 합이 된다.
'백엔드 > SQL' 카테고리의 다른 글
| 데이터베이스 설계와 개체-관계 모델 (0) | 2025.05.27 |
|---|---|
| SQL을 활용한 데이터 집계와 분석(2) (0) | 2025.05.26 |
| JOIN (0) | 2025.04.17 |
| DML: SQL 연산자와 내장함수(2) (0) | 2025.04.15 |
| SQL 8장 (0) | 2025.04.14 |



