테이블 데이터의 저장과 접근
buffer manager은 자주 접근되는 데이터를 RAM의 버퍼 캐시 메모리에 올려두는 역할을 한다.
file manager은 디스크의 메모리 공간을 관리한다.
네일 영양제를 조회하기 위해 클릭하면 상세 페이지로 이동하는데,
상세 페이지에는 '네일 영양제' 행을 SELECT한 결과를 볼 수 있다.
id, 제조사, 가격을 볼 수 있는 것이다.
1. 이때 데이터에 접근하기 위해 먼저 RAM의 캐시 공간을 보고 없으면 디스크로 가서 본다.
2. 없으면 데이터 파일에서 완전탐색을 해 찾아내 해당 정보를 캐시에 올려둔다.
* 데이터베이스 테이블의 ROW는 삽입된 순서대로 저장되어 있기 때문에 정렬된 상태가 아님 -> 완전탐색해야 함
==> 검색 속도 향상을 위해 "인덱싱" 기술 필요

인덱스
인덱스란
: 데이터베이스에서 특정 컬럼을 기준으로 빠르게 데이터를 조회하기 위해 생성하는 자료구조
-> 어떤 테이블 특정 컬럼에 인덱스 걸어주면
-> (키, 값) = (col 값, 해당 row의 주소)를 저장하는 자료구조 생성
-> 키를 통해 값(해당 row의 주소) 알아내 데이터 바로 가져오기 가능
: 검색 조건/조인 조건 등으로 자주 쓰이는 컬럼에 인덱스 생성
* 여러 컬럼에 걸 수도 있지만 너무 많은 자료구조가 생성되므로 성능 저하
: 디스크 내 indices에 저장
명시적 인덱스 생성
<구문>
create index INDEX_NAME on TABLE_NAME(TARGET_COLUMN);
<예시>
create index hiredate_index on employee(hire_date);
<생성된 인덱스 확인>
show index from employee;자동으로 생성되는 인덱스
PRIMARY KEY, FOREIGN KEY, UNIQUE 제약조건을 가진 키에는 내부적으로 인덱스 자동 생성
B+ TREE
: 관계형 DB에서 대표적으로 사용되는 인덱스 자료구조
- 한 노드의 자식이 많을수록 트리 높이가 낮아져 탐색 경로가 짧아지고 디스크 I/O 횟수 적음
- 루트를 포함한 내부 노드의 인덱스: (키, 다른 노드로의 포인터) 저장 -> 탐색
- 리프 노드의 인덱스: (키, 키를 포함한 ROW의 시작 주소) 저장 -> 실제 데이터 탐색

- 삽입/삭제 발생 시 자동적으로 항상 균형 유지 (자기 균형 트리)
- 삽입할 때는 균형 유지해주지만,
삭제하면 사용하지 않는다는 표시만 있을 뿐 데이터가 없어지지 않음 -> 성능 저하
- UPDATE는 삭제 후 삽입하는 것 -> UPDATE 연산이 많으면 인덱스 사용 불리
- 검색/삽입/삭제 모두 O(logN)에 처리 가능
- 데이터셋 크기가 작을 경우, B+ TREE보다 테이블 완전 탐색이 더 빠를 수 있음
인덱스 파일과 데이터 파일
- 인덱스 자료구조는 데이터베이스의 "인덱스 파일"에 물리적으로 저장되어 유지
- 실제 데이터는 "데이터 파일"에 저장되어 유지
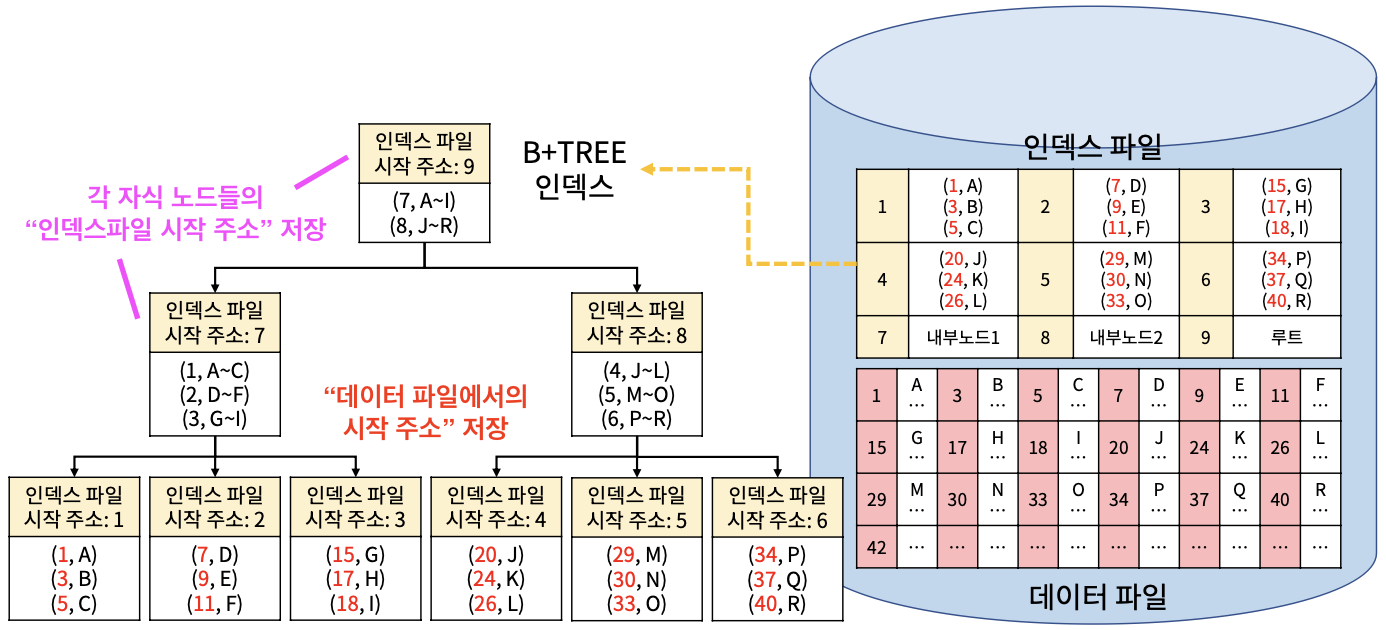
buffer manager가 버퍼 캐시 메모리에 접근해 B+Tree의 루트 노드 있는지 확인
-> 없으면 buffer manager가 인덱스 파일 접근
* 루트 노드에서 찾고 싶은 문자열 따라서 리프노드까지 옴(각 노드 거칠 때마다 버퍼 캐시 메모리에 저장)
-> file manager가 데이터 파일 접근
* 리프노드에서 가리키고 있는 주소를 디스크 내 데이터 파일에서 찾아 버퍼 캐시 메모리에 저장 후 가져옴

인덱스의 장단점
(+) 검색 속도 향상
(+) 순차 탐색 및 정렬 성능 향상
* 리프노드에 정렬된 데이터들은 정렬돼있기 때문에
(+) 조인 성능 향상
(-) 인덱스 생성, 유지에 비용 필요(저장 공간, 처리 오버헤드 등 ..)
(-) 삽입/삭제/갱신 시 오버헤드 발생(특히 갱신 INSERT)
(-) 옵티마이저 동작에 혼란 야기 -> 기존 쿼리의 성능 저하
인덱스 설계 원칙
1. 너무 많은 인덱스는 오히려 성능 저하 -> 적당한 수만 유지하고 불필요한 인덱스는 주기적으로 삭제 필요
2. SELECT 를 통한 조회 조건 또는 조인 조건에 자주 등장하는 컬럼에 대해서만 생성하자
3. 다양한 값을 갖는 컬럼에 대해 인덱스를 생성하는 것이 더 효율적 (ex. '성별' 컬럼 < '주민번호' 컬럼)
'백엔드 > SQL' 카테고리의 다른 글
| 쿼리 프로세싱과 최적화 (0) | 2025.06.03 |
|---|---|
| 트랜잭션 (0) | 2025.05.31 |
| 관계 데이터베이스 설계 - 함수 종속성과 정규화 (0) | 2025.05.28 |
| 데이터베이스 설계와 개체-관계 모델 (0) | 2025.05.27 |
| SQL을 활용한 데이터 집계와 분석(2) (0) | 2025.05.26 |



