Adverserial attack(적대적 공격)이란
Adverserial attack의 의미
Adverserial attack이란 딥러닝 모델의 내부적 취약점을 이용해 만든 특정 노이즈값을 이용해 의도적으로 오분류를 이끌어내는 입력값을 만들어내는 것이다. 이때 만들어지는 입력값을 "적대적 예제(Adverserial Example)"이라고 하며 이 조작된 입력값은 딥러닝 모델을 속여 공격에 취약하게 한다."특정 노이즈 주입 -> 적대적 예제 생성(잘못된 입력 주입) -> 모델 속임"

예컨대 위처럼
모델이 57.7%의 confidence로 "panda"라고 인식한 그림에 어떠한 noise를 주입하면,
사람의 눈에는 그대로 "panda"로 보이지만 모델은 99.3%의 confidence로 "gibbon"으로 인식해 버린다.
입력값을 어떻게 조작하는지에 따라 다양한 방법이 있지만
오늘 살펴볼 방법은 gradient 알고리즘을 사용하는 방법이다.
Adverserial attack의 종류
White-box Attack vs Black-box Attack
- White box attack
attacker가 target model에 모든 접근 권한을 가짐 -> weight, model architecture 등에 대한 정보를 알 수 있음
gradient-based optimization -> target model network의 error를 최대화하는 adversarial example 생성
- Black box attack
attacker가 target model에 대한 정보를 알 수 없음 -> 모델에 특정 값을 입력했을때, 이에 대한 출력값만 볼 수 있음
gradient computation 수행 불가 -> target model의 입출력을 관찰하고 모방하여 adversarial example을 생성
Gradient Adverserial Example
: White box attack
: 주어진 모델의 weight 값을 이용해 gradient 값을 계산 -> 입력값 조작
- FGSM(Fast Gradient Sign Method)
: 적대적 공격을 통해 adverserial example(적대적 예제)를 만드는 노이즈
: 제한 - 생성된 노이즈의 분포 중 각 픽셀들의 절댓값이 정해진 크기보다 클 수 없음
: cost function L이 주어졌을 때 딥러닝 모델의 파라미터 θ를 이용하여 정답 라벨 y에 반대되는 방향으로 gradient를 업데이트하여 오분류 초래
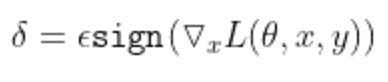
1. 주어진 input x를 model에 입력값으로 줌
2. 입력값에 따른 gradient 계산
3. target class가 정해지지 않은 경우 ground-truth class와 반대되는 gradient ascent를 수행
4. target class가 정해진 경우 target class로 gradient descent 수행
class FGSM(Attacker):
def __init__(self, model, config, target=None):
super(FGSM, self).__init__(model, config)
self.target = target
def forward(self, x, y):
x_adv = x.detach().clone()
if self.config['random_init']: #Random Start Flag
x_adv = self._random_init(x_adv)
x_adv.requires_grad = True
self.model.zero_grad()
logit = self.model(x_adv) #Projection
if self.target is None:
cost = -F.cross_entropy(logit, y) # Gradient ascent
else:
cost = F.cross_entropy(logit, self.target)
if x_adv.grad is not None:
x_adv.grad.data.fill_(0)
cost.backward()
x_adv.grad.sign_() #applying sign function
x_adv = x._adv - self.config['eps']*x_adv.grad #x_adv = x + delta
x_add = torch.clamp(x_adv,*self.clamp)
return x_adv
- PGD(Projected Gradient Descent)
: FGSM 반복 수행 -> gradient를 업데이트하고 더 강력한 adversarial example을 생성하는 방법
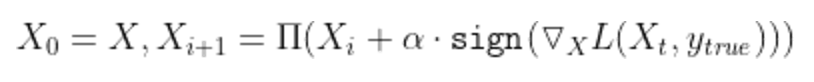
class PGD(Attacker):
def __init__(self, model, config, target=None):
super(PGD, self).__init__(model, config)
self.target = target # 오분류할 target class가 정해진 경우
def forward(self, x, y): # x: test input, y: test input의 ground truth class label
x_adv = x.detach().clone()
if self.config['random_init']: # Random start flag
x_adv = self._random_init(x_adv)
for step in range(self.config['attack_steps']):
x_adv.requires_grad = True
self.model.zero_grad()
logit = self.model(x_adv) # Projection
if self.target is None: # gradient ascent
loss = F.cross_entropy(logit, y, reduction='sum')
loss.backward()
grad = x_adv.grad.detach()
grad = grad.sign()
x_adv = x_adv + self.config['attack_lr'] * grad
else: # gradient descent
assert self.target.size() == y.size()
loss = F.cross_entropy(logit, self.target)
loss.backward()
grad = x_adv.grad.detach()
grad = grad.sign()
x_adv = x_adv - self.config['attack_lr'] * grad
# Projection
x_adv = x + torch.clamp(x_adv-x, min=-self.config['eps'], max=self.config['eps'])
x_adv = x_adv.detach()
x_adv = torch.clamp(x_adv, *self.clamp)
return x_adv
'연구 > Deepfake로부터 안전한 사진 변환 서비스' 카테고리의 다른 글
| [논문 리뷰]Deepfake Detection: A Systematic Literature Review (0) | 2025.03.28 |
|---|