컴퓨터 구조 수업에서 하드웨어의 계층에 대해 배운 바 있다.
S3는 가장 하위 계층인 storage부분에 해당한다.
컴퓨터가 데이터를 저장하기 위해 두 가지 storage방식을 사용한다.
1. On-premises
: 기관이 직접 보유한 storage
(-) 많은 장비를 두어야 하므로 upfront cost 비쌈
(+) 기밀을 안전하게 지킬 수 있음
2. cloud storage
: 기관 밖 cloud에서 제공해주는 storage 서비스
(+) 쓰는 만큼 지불 => cost efficient
(+) 보안성 좋음(데이터를 여러 서버에 나눠서 store하기 때문에 server attack 시 위험 부담 적음)
(+) 다수의 사용자 수용 가능
(+) workload에 따라 scaling 가능
(+) server 관리 필요 없어 간편
(+) cloud가 데이터 복사본을 여러 개 가지고 있으므로 EC2가 shut down했다고 해서 데이터 사라지지 않음

Cloud Storage 종류
1. Block Storage
- 데이터를 block 단위로 나누고 각 block별로 고유의 identifier와 함께 보관
- OS나 SAN(Storage Area Network)에 의해 운영
(+) performance: low-latency access(속도 빠름) & high IOPS(Input/Output Operations Per Second)
(+) flexibility: 데이터가 잘게잘게 쪼개져 있음
(+) reliability: 데이터를 복제해놓아 손실을 막음
ex. high-performance databases, virtual machine file systems
2. File Storage
- 계층적 구조에 따라 데이터 정리
- 개인 컴퓨터의 file 형태로 저장 및 접근됨
- NFS, SMB 등 file system protocol에 의해 접근 가능
(+) simplicity: file형식은 친숙한 모델이므로 사용이 편리함
(+) collaboration: 다수의 사용자가 file sharing 가능
(+) compatibility: 다른 OS라도 같이 사용 가능
ex. shared file repositories, content management systems
3. Object Storage
- file들이 속성 별로 구분돼 object형태로 저장됨
- 각 object들은 data, metadata, object key로 구성됨
- metadata란 object size, purpose 등의 object 정보
- object key란 object의 고유 식별자 (고유 식별자의 API를 통해 접근 가능)
- bucket은 object를 담고 있어 object끼리 구별해준다. (bucket 이름+key+version ID)
- flat address 형태 => hierarchy 없음(모든 object 같은 레벨)
- object들은 고유 식별자(ID)를 통해 retrieve됨
- metadata-rich object(많은 정보 포함)
- distributed storage system(node 여러 개 둠으로써 horizontal scaling & 데이터 복제를 통해 reliability)
- HTTP/HTTPS와 같은 프로토콜을 사용한 web-based API 통해 접근 가능
(+) scalability: 대량의 정보 처리 가능
(+) metadata: 확장형 metadata
(+) cost-effectiveness: 적은 비용으로 대량 dataset 저장에 적합
ex. cloud storage services, backup and archival solutions ..


쉽게 비유해보자면 ,,,
Block Storage같은 경우는 데이터들이 종이조각에 조각조각 저장돼있다. (block)
File Storage같은 경우는 캐비넷(=directory)의 서랍(=file)에 저장돼있다.
Object Storage같은 경우는 상자(=object)에 저장돼있고, QR코드(=identifier)로 식별된다.
=> file storage 는 엄격한 기준으로 정리돼있어 비교적 유연성이 부족하며,
object storage는 block storage보다는 느리지만 정리가 필요하지 않고
QR코드만으로 식별 가능하므로 빠르게 데이터 처리가 가능하여 유연성이 꽤 높다.
Object storage의 예: Dropbox
key(UUID) + data + metadata

S3
AWS의 storage service에는 세 종류가 있다.
EBS(Elastic Block Service):
EFS(Elastic File Service):
S3(Amazon Simple Storage Service): object storage 형태를 가진 storage service
위와 같은 file을 S3에 업로드하면 그 파일이 최소 3개로 복제되고,
3개의 파일은 서로 다른 availability zone을 가진 instance로 전달된다.(durabiliy & availability)
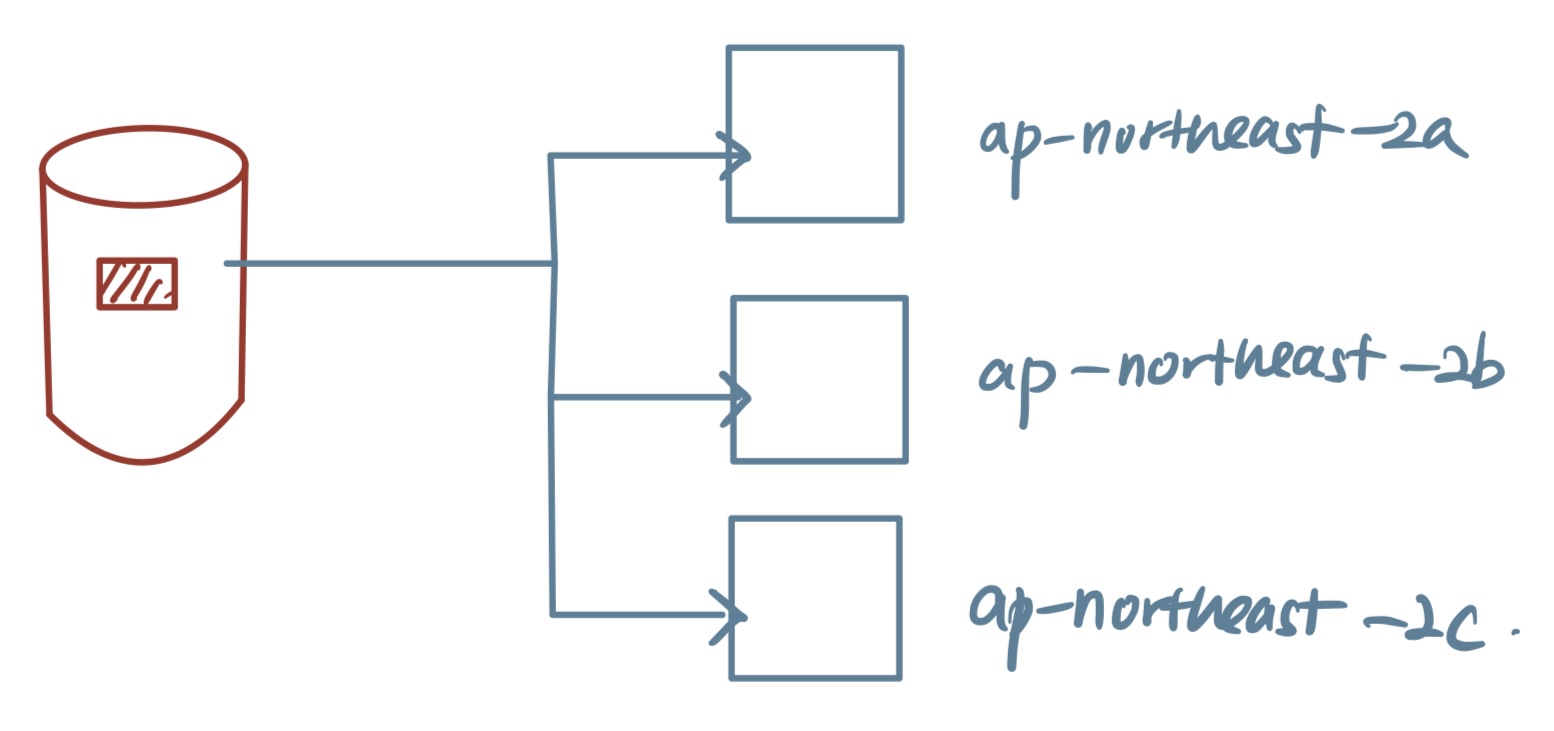
S3의 이점
- scalabtility
- durability: loss와 관련된 것 => durability 99%이면 파일 100개 중 99개만 보존된다는 뜻
aws는 99.999999999%
- availability: 연도별 object에 접근할 수 있는 날짜 수(90%이면 36.5일은 접근 못 한다는 것)
aws는 99.9%
- performance
- security
AWS S3 Storage Classes
1. Active storage
: 항상 쓰는(또는 빠른 접근이 필요한) 데이터 저장
ex. files for static website
2. Archive storage
: 가끔씩만 쓰지만 필요한 데이터 저장
ex. data for compliance or video archive

- Amazon S3 Standard: static content만 포함, log file
- Amazon S3 Standard-Infrequent Access: backups, 자주 접근하지는 않지만 빨리 접근해야 하는 file들
- Amazon S3 One Zone-Infrequent Access: 다른 S3 bucket으로부터 오는 replication backups
- Amazon S3 Glacier Flexible Retrieval: 장기적 backup에 필요
- Amazon S3 Glacier Deep Archive: 장기적 data libraries
- Amazon S3 Intelligent-Tiering: 예측 불가능한, 알려지지 않은, 자주 바뀌는 workload
'클라우드 > AWS' 카테고리의 다른 글
| Networking (1) (0) | 2024.12.22 |
|---|---|
| Security(1) (1) | 2024.11.22 |
| AWS EC2(2) (4) | 2024.11.07 |
| AWS EC2(1) (6) | 2024.10.08 |
| 클라우드컴퓨팅이란 (3) | 2024.10.04 |



